지난 포스팅에서 잠시 말씀드렸던, 검색 기술 컨퍼런스에 다녀왔습니다.
생각 했던 것 보다(?) 많은 분들이 오셔서 약간 놀라웠습니다. 국내에 이렇게 검색 기술에 관심이 있는 사람들이 많았나 하는 생각도 들었고요, 내용을 다 듣고 나오면서 드는 생각은 업체 측에서 일반기업 이라든가, 관련 기관에도 홍보를 충분히 하지 않았나 하는 생각도 살짝 들었습니다. 마치 도서관으로 따지면 도서관 대회 같은 느낌이랄까요... :-)
전체적인 느낌을 말하자면, 솔직히 마케팅을 위한 장이라는 생각이 많이 들었고요, 각 트랙에서도 당연한 것이겠지만, 패키지나 솔루션을 광고하는 듯한 느낌이 많이 들었던 것은 사실입니다. 하지만 이러한 행사나 이벤트가 많이 이루어져야 검색시장도 활성화 되고, 많은 사람들의 인식이 좋아질 거라는 면에서는 아주 바람직한 현상이지만, 내년에도 아님 가까운 시일 내에 이러한 행사가 있다면 좀 더 기술적인 면을 알리고 토론할 수 있는 형태의 모임이 이루어지면 더 좋지 않을까 하는 생각을 해보았습니다.
제가 참석했던 세미나에 대해 잠깐 언급을 해보겠습니다. 내용을 언급하기 보다는 제가 느낀점이나 나름대로 생각했던 것 위주로 적어내려갈 생각입니다. 발표하신 분의 의견이 아니니 오해 없으셨으면 합니다.
첫 번째 트랙으로는 모란소프트의 조영환 박사님의 '온라인 평판의 수집과 분석기술'입니다. 과거의 평판의 시작은 미디어(TV, 신문 등)를 통한 Off-line 중심이었다고 한다면 지금은 블로그나 게시판 카페 등을 통한 On-line 평판이 점점 커져가고 있는 것 같습니다.
전자의 경우를 뚝배기에 비유한다면, 후자의 경우는 전자렌지 정도라고 할 수 있을 것 같습니다. 전자렌지에 데운 음식은 금새 따뜻해지지만, 그 영향력이나 지속력이 전자에 비해서는 떨어지고, 개인적인 생각으로는 좀 더 가볍게 받아들여질 수 있지 않나 생각도 들었습니다.
하지만 최근 광우병 사태나 먹거리 관련 이런 저런 얘기들을 보자면, 솔직히 이제는 On-line 미디어가 오히려 더 큰 파급력을 가지게 되는게 아닌가 하는 생각도 듭니다.
평판(Reputation)에 대한 강좌를 듣고 있으면 이전에 실험했던 Opinion Mining과 아주 유사하거나 동일한 개념이지 않나 하는 생각이 들었습니다. 관련 논문을 읽으면서 "이거 뭔가 비즈니스적으로 사용할 수 있는 분야는 마케팅 밖에 없겠는걸.. " 하는 생각이 들었던 것이 사실이구요, 조박사님께서 발표해주신 내용에서도 언급해주셨는데, 현재 외국에서는 B2B와 B2C모두 서비스 중인 예들을 보여주셨고, 국내의 사례도 얘길 해주셨습니다.
하지만 결국 이러한 것으로 무엇을 할래? 한다면 이런 것들이 있을 것 같습니다.
기업의 브랜드 이미지 분석 (마케팅용, B2B)
특정 오브젝트의 선호도 또는 인기도 등의 시장조사 (추천용, B2C)
굳이 오브젝트라고 표현 한 이유는 이러한 대상이 사람이 될 수도 있고, 제품이 될 수도 있기 때문이며, 목적에 따라 다양한 무언가가 될 수 있기 때문입니다.특정 오브젝트의 선호도 또는 인기도 등의 시장조사 (추천용, B2C)
현재 네이버랩에서 이와 유사한 '긍정 부정 검색'을 실험해 보실 수 있습니다.
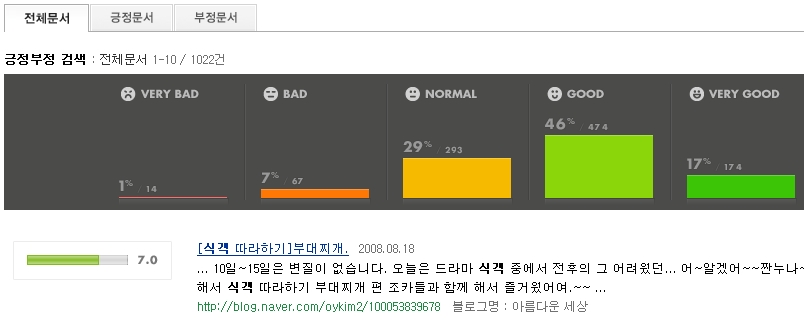
평판 분석 시스템의 전체적인 흐름을 나름대로 구성해 보았습니다. 우선 분류나 군집화 등의 마이닝 기술이 적용되어야 하는 제약 때문에 도메인 한정이 되지 않으면 사실 어느정도 이상의 품질이 나오지 않음을 감안하였습니다. (조박사님께서 발표 내용중에 도메인 한정에 대한 언급도 해주셨습니다.)
분석을 위한 특정 도메인 선택 (뉴스, 블로그, 쇼핑몰, 특정 게시판 등)
해당 도메인에 한정된 특질 추출 (댓글의 특성, 이용패턴, 구어/속어 및 문법오류 등)
도메인 분류를 위한 학습모델 생성 (기 분류된 학습 문서 필요)
선택된 도메인에 한정한 크롤 (해당 도메인으로 분류된 문서만 수집)
추출된 특질을 통한 휴리스틱 및 규칙 생성 (패턴을 사전화, 문장유형, 구조 등 고려)
도메인에 독립적인 일반적인 규칙 생성 (도메인 패턴과 비교하여 생성, 충돌고려)
수집된 문서의 벡터화 (텀을 추출하는 것이 아니라 패턴사전과의 매칭을 계산)
문서에 대한 점수 계산
해당 도메인에 한정된 특질 추출 (댓글의 특성, 이용패턴, 구어/속어 및 문법오류 등)
도메인 분류를 위한 학습모델 생성 (기 분류된 학습 문서 필요)
선택된 도메인에 한정한 크롤 (해당 도메인으로 분류된 문서만 수집)
추출된 특질을 통한 휴리스틱 및 규칙 생성 (패턴을 사전화, 문장유형, 구조 등 고려)
도메인에 독립적인 일반적인 규칙 생성 (도메인 패턴과 비교하여 생성, 충돌고려)
수집된 문서의 벡터화 (텀을 추출하는 것이 아니라 패턴사전과의 매칭을 계산)
문서에 대한 점수 계산
결국 분류나 군집화를 통한 범위를 한정하는 것과 문서에서 긍정/부정을 구분하기 위한 실마리(특질) 찾는 과정이 핵심기술이라고 생각됩니다. 큰 틀에서 검색에서의 랭킹모델을 만들어내는 것과 많이 닮아 있다는 생각을 내내 떨처버릴 수 없었구요, 좀 더 어렵겠구나 하는 생각만 자꾸 들었습니다. ^^
두 번째 트랙은 솔트룩스의 안태성 부장님이 발표해주신 '사용자에게 통찰력을 주는 검색, 토픽랭크'라는 세션입니다. 기술적인 내용보다는 아무래도 이번에 구축된 서비스 위주로 설명이 되어서 약간 아쉽다는 느낌이었구요, 발표를 듣기전에 저는 베타테스터로 신청 및 가입완료가 되었다는 메일을 받았음에도 불구하고 로그인이 되지 않아 약간 불안정한 상태였다는 점이 조금 아쉬웠습니다.
아울림이라는 서비스인데 언듯 보기에는 3SOFT의 MFeed 서비스와 컨셉이 비슷한 것 같다는 느낌을 받았었구요, MindMap과 같은 형태의 인터페이스로 이용자에게 직관적으로 제공한다는 점이 신선한 것 같습니다. 하지만 약간 우려되는 점은 이러한 인터페이스에 아직 익숙하지 않는 대다수의 이용자들의 마음을 어떻게 잡을 것인지가 가장 관건인 것 같습니다.
세 번째 트랙에 오니 벌써 지치는 군요 -_-;; 그래도 하얀눈길님의 발표였으니 꾹 참고 끝까지 포스팅을 해보렵니다. ^^
오픈베이스에 근무하시는 '검개그 카페지기'이시기도 한 이상호 수석연구원님께서 발표해주신 '개인화를 통한 모바일 검색 서비스' 입니다. 예전 검개그 오프모임 때에 한번 언급된 토픽이라 좀 더 가볍게 들을 수 있었는데, 그 때 보다는 좀 더 재미있게 들었던 것 같습니다.
결국 모바일을 통한 서비스의 가장 큰 장점은 'Identity' 와 'Location' 인 것 같습니다. 다른 어떤 서비스에서도 제대로 파악하기 힘든 정보를 모바일에서는 당연한 듯이 사용할 수 있다는 점입니다. 하지만 물론 프라이버시 문제와 로그분석에 따른 기술적인 한계 및 비용적인 문제 등이 가장 큰 걸림돌이 되긴 합니다.
이러한 한계를 넘어설 수만 있다면 흔히들 일반 검색분야에서 찾아내기 힘든 두 가지 정보를 이용하여 이용자의 의도 (INTENTION)을 얻어낼 수 있을 것이며, 개인화 서비스의 새로운 장이 열리지 않을까 하는 생각에 두근 거리기 까지 했습니다.
아주 재미있는 세 가지 예를 들어주셨는데, 딴지를 한 가지 걸어보자면, '네이버의 지식인 검색을 모바일에 적용하는 예'에서 모바일의 가장 큰 장점인 Identity와 Location에 초점이 맞추어 진 것이 아니라 Spam을 제거하는 점에 초점을 맞추어 설명해 주셨던 것 같습니다. 물론 개인적인 취향과 환경설정이 반영되는 면에서는 적절한 예라고 생각될 수 있으나 잘못된 답변이나 Spam 및 광고 등을 제거하는 차원에서는 모바일이 아니더라도 현재 지식인에 바로 적용하여도 크게 이상할 것이 없을 것 같습니다. 그냥 딴지라고 생각해 주십시요 :-)
두번째 예에서 말씀해주신 서비스의 경계를 넘어선 로그정보 공유를 통한 서비스가 안전하게만 사용된다면 정말 재미있는 결과가 나오지 않을까 생각되었고요, 마지막 예제인 '가까이 있는 내 연인을 인식하여 애인이 즐겨듣는 노래를 추천해주는' 서비스도 실제로 프라이버시 문제만 잘(?) 풀어낸다면 대박 서비스이지 않을까요? ^^
마지막 세션으로는 강승식 교수님의 '형태소 분석과 언어처리 도구'라는 세션이었습니다. 첫 번째 세션의 조박사님과는 사뭇 다른 느낌으로(?) 다가오는 세션이었습니다. 조박사님께서 트랜디한 아이디어 위주의 서비스 또는 기술을 연구하시는 분이라고 친다면, 강박사님께서는 연구실 내에서만 나올 수 있는 생도들을 키울 수 있는 또는 학습을 위한 도구를 개발하시는 분이라는 생각이 들었습니다. 과연 경험과 노하우가 많으신 교수님 답게 이런 저런 재미있는 이야기와 위트를 섞어가면 강연을 해주셨고, 정말 의미있는 도구와 팁을 소개해 주셨습니다.
우선 가장 눈에 띄는 것은 색인어 추출에 있어서 일반적인 키워드 또는 어절분할 색인 외에 토큰과 태그를 조합하여 색인해보면 어떨까 하는 점에서는 색인어 추출 보다는 오히려 분석에 유용하지 않을까 하는 생각도 들었습니다.
그리고 미등록어 추출 및 오류유발 미등록어 추출 등의 도구는 검색서비스를 위해서 언어처리 관련 작업을 해보신 분이라면 쌍수들고 환영할 만한 도구라는 생각이 들었구요, 이 외에도 분류시스템, 자동 띄어쓰기, 문장분리기 등의 도구와 더불어 각종 해외 도구를 많이 소개해 주셨습니다. 또한 몇 몇 좋은 예제로 프리젠테이션이 직관적이고 이해하기 쉬우며 집중력이 높아질 수 있다는 것에 감동 받았습니다. 역시 언어처리 관련 분야는 단어 하나 문장 하나만 잘 찾으면 쉽게 전달 되는 것이 아닐까 하는 생각도 들었습니다.
그리고 가장 인상적이었던 말씀이 'On-demand'로 기능을 구현하고 제품을 만들어 주실 수 있다는 얘기에 '역시~~' 하면서 웃음지을 수 있었습니다. ^^
끝으로 CoNLL(Computational Natual Language Learning) 이라는 언어처리 관련 대회에 대해서도 언급해 주셨는데, Sentence Detection에 관한 대회도 있었다고 해서 제 논문 주제와도 유사한 것도 포함되어 있구나 하면서 '나도 한번?' 하면서 솔깃 해지기도 햇습니다.
솔직히 기술적인 내용에 대한 시간이 상대적으로 부족했었고, Q&A 시간도 없을만큼 빡빡한 일정이라 좀 불만이 없었던 것은 아니었지만, 현재 검색에 대한 트랜드가 이러 이러한 것들이 얘기되고 있구나 하는 생각이 들어 나름대로 좋았던 것 같습니다.
최근에 Introduction to Information Retrieval 이라는 책을 아마존을 통해서 구매하게 되었는데, 이 책의 목차를 쳐다보고 있노라면, 현재 검색 트랜드가 눈 앞에 선한 것 같다는 생각을 하게 됩니다.
Text Mining, Information Extraction and Data Analysis, Language Processing, Semantic Web, Classification, Clustering, Machine Learning
오히려 이제는 Information Retrieval 이라는 키워드 보다는 Data Mining and Analysis 그리고 Language Processing 에 관련된 키워드가 더 각광받는 시기가 오지 않았나 하는 느낌이 들 정도로 트랜드가 변화하고 있는 것 같습니다.
'정보검색 > event' 카테고리의 다른 글
| '검색 기술 컨퍼런스'가 오는 9월 2일 개최된다고 합니다. (0) | 2008.08.07 |
|---|
